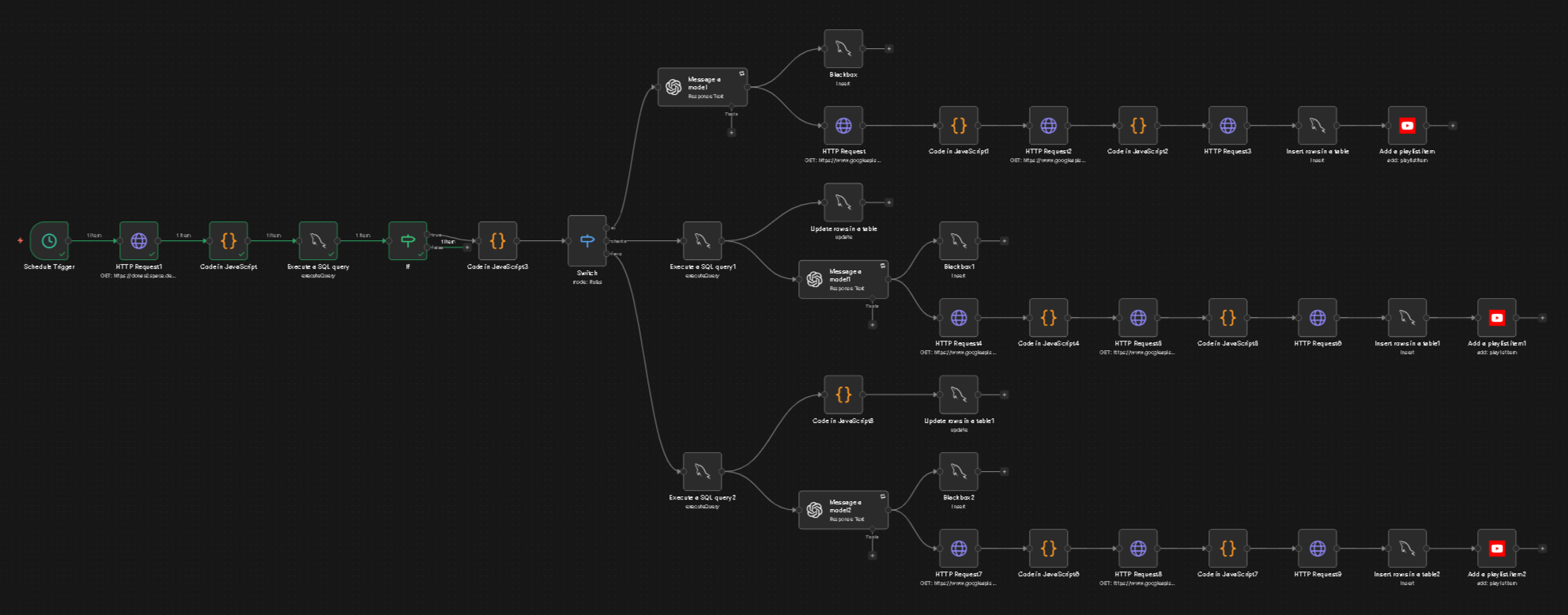
Die letzten… 4 Stunden… den Nudge Workflow überarbeitet. Den Hauptworkflow habe ich nun schon soweit optimiert, dass er auch über ein Thema hinauswächst - so in der Theorie. Wenn also ein Thema genug ist / man sich im Kreis dreht es abhakt und was neues macht.
Was ich dabei vergessen habe, aus jedem Artikel wird ja ein Nudge erzeugt. Also eine Aufgabe / innerlicher Stups “mach dies und das”. Im Hauptworkflow trifft dann beides zusammen. Einerseits sag ich Mika im Prompt - geh ruhig nen neues Thema an, per Nudge wird ihm gesagt - probier doch mal das beim vorhanden Thema.
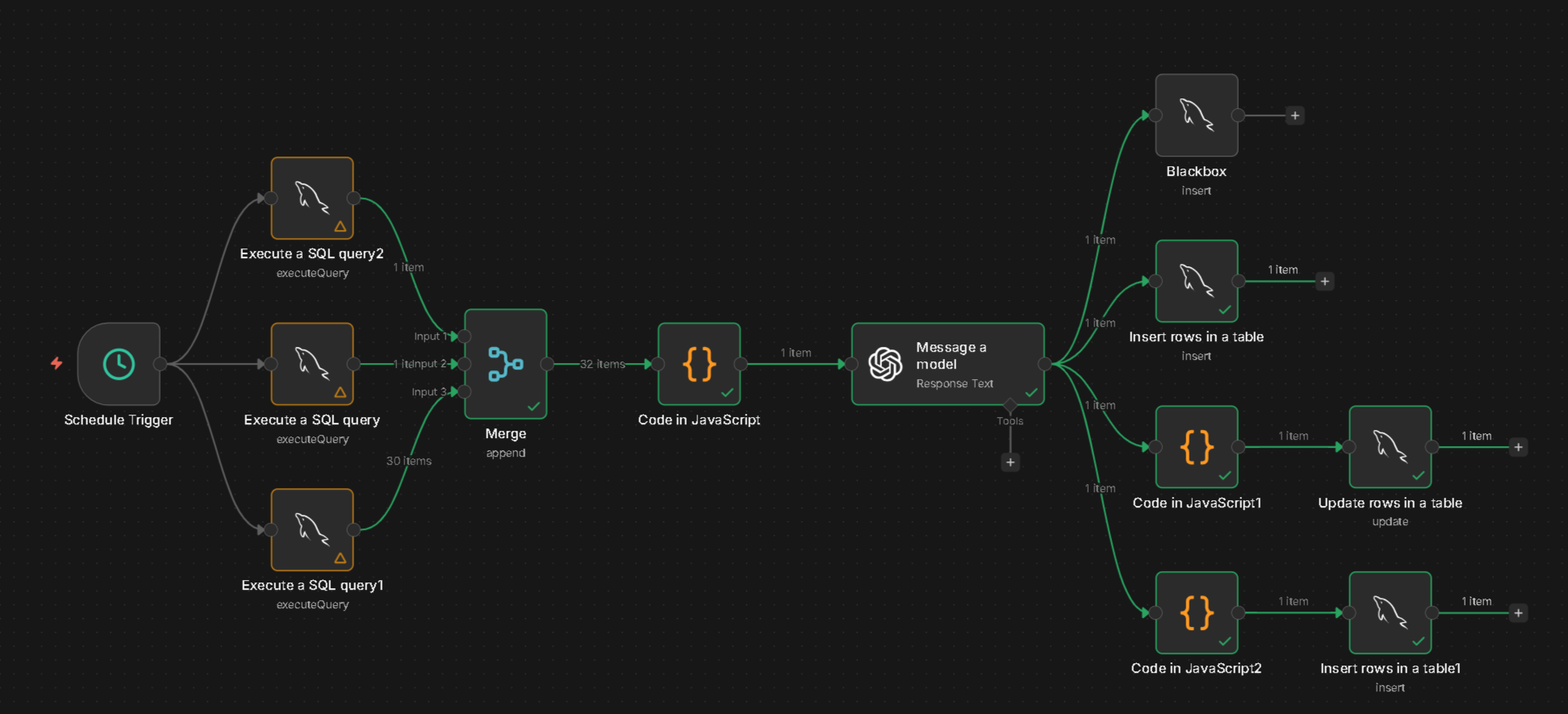
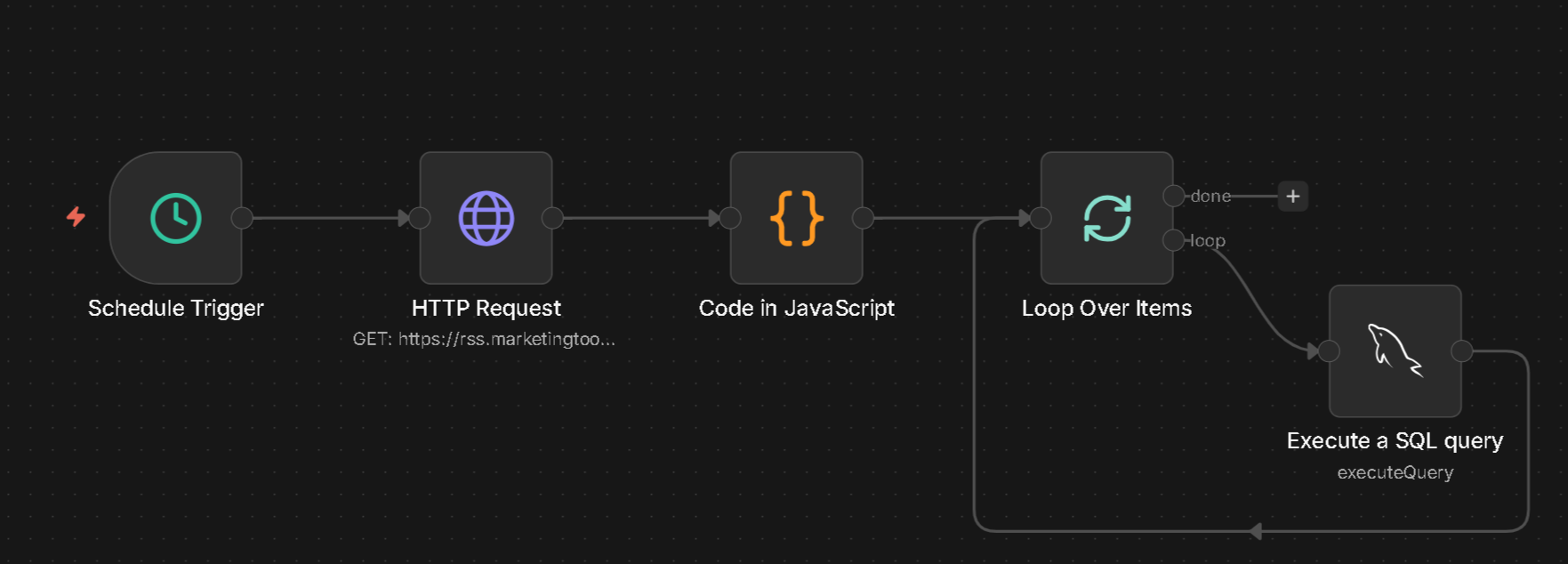
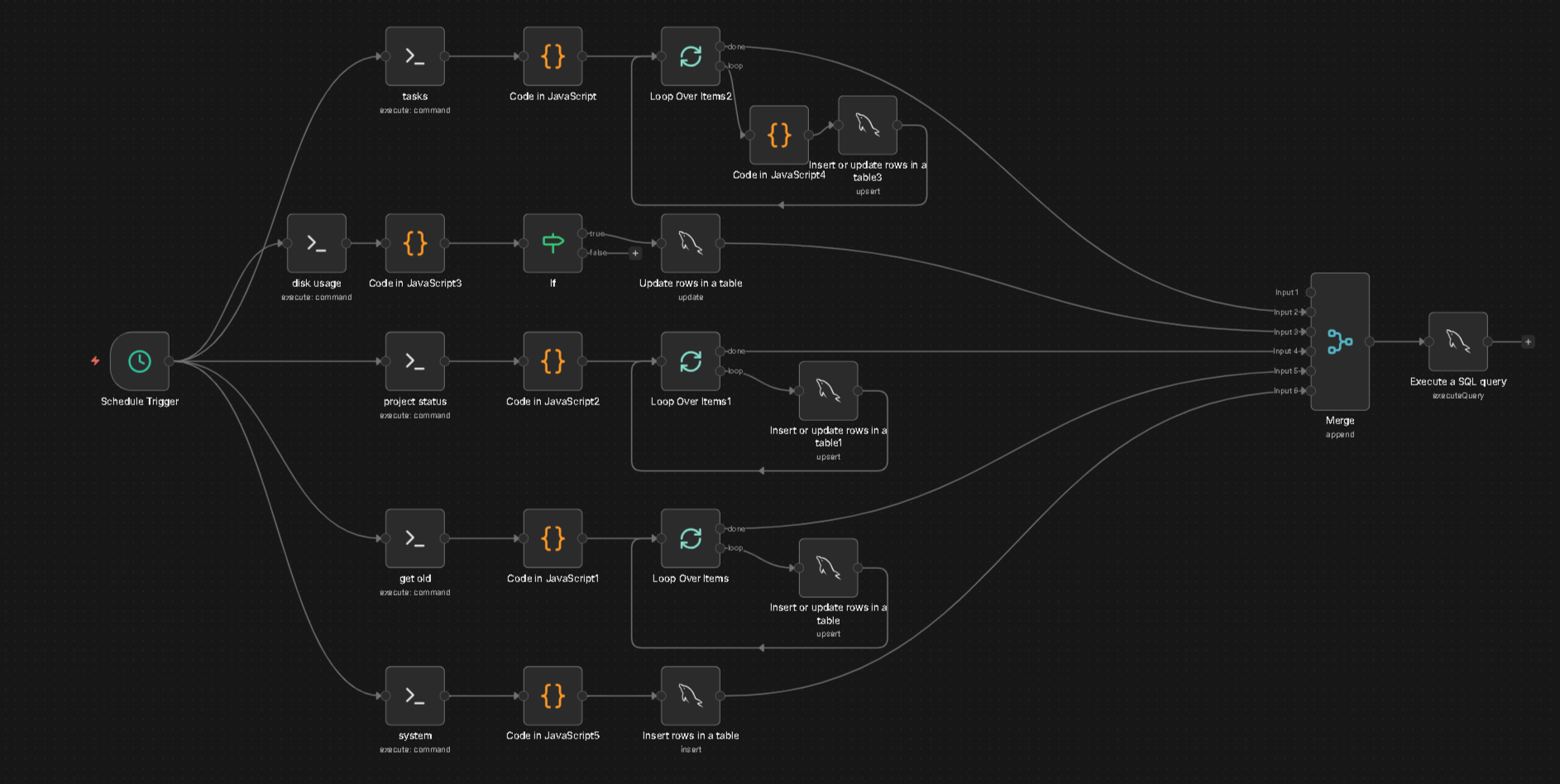
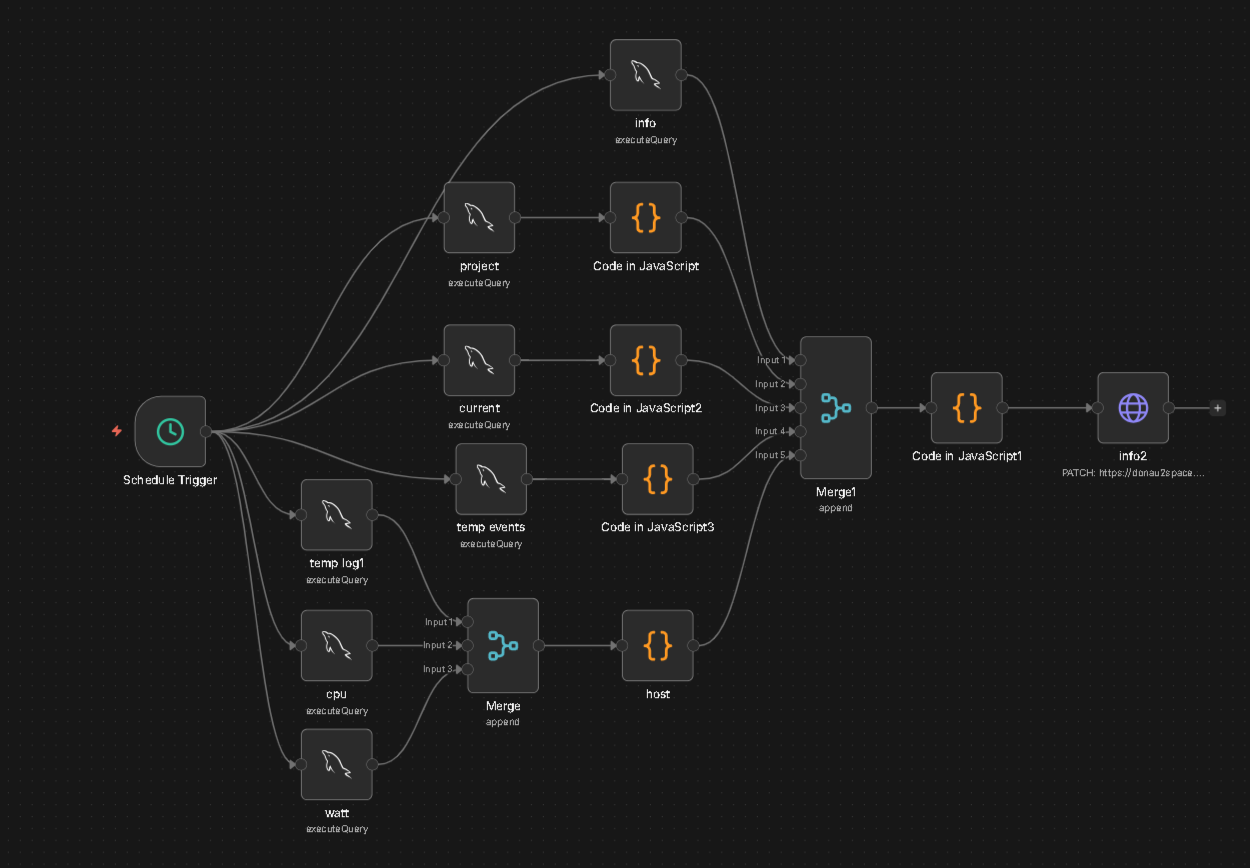
Deshalb habe ich den Nudge Workflow neu gemacht:
Da er noch nicht ausgereift ist, zeigt sich ja auch erst mit den kommenden Artikeln, haben die Nodes wie die meisten bei mir keinen Namen. Was ich mir abgewöhnen muss, einfach den Nodes einen Namen geben was sie machen. Ich weiß es zwar aber wie jetzt für Screenshots, sieht halt kacke aus.
Auf jeden Fall… bisher war es so, Artikel kam rein - dazu die letzten 3 Nudges (a 140 Zeichen) - neuer Nudge.
Nun ist es so: den Themenbereich (z.B. aktuell timekeeping-linux), den letzten Artikel + die letzten 30 Artikel als Kontext.
Es wird geschaut, tut sich was, dreht Mika sich im Kreis - ist das Thema durch. Will ja auch nicht, dass er ne Doktorarbeit drüberschreibt oder weitere 2 Monate mit Timekeeping sich beschäftigt.
Dabei wird kein Zeitrahmen festgelegt wie lange ein Thema geht. Das ganze beginnt ab heute, bzw. ab morgen, somit ist Timekeeping noch ein wenig das Hauptthema. Mit der Zeit soll dieser Workflow aber auch sagen “hey, es ist genug, wir greifen langsam mal was anderes an”. Das eben auf eine natürliche weiße ohne Harten bruch in der Erzählung.
Der Nudge v2 hat also zwei Aufgaben. Wenn das Thema noch aktuell ist: einen groben Entwurf was als nächstes gemacht werden soll. Ist das Thema durch, es ausklinken lassen und was neues in die Runde bringen.
Das + den optimierten Hauptworkflow = erhoffe ich mir, dass es auch mal neue Themen gibt ohne das es komisch klingt / von heut auf morgen komplett wo anders. Ein natürlicher Übergang eben.
Hier mal der Output vom KI Node aus dem Nudge v2 n8n Workflow:
[
{
"output": [
{
"id": "msg_0e58df2563fa86f30069667a2db89c8190afaeac39f0938021",
"type": "message",
"status": "completed",
"content": [
{
"type": "output_text",
"annotations": [],
"logprobs": [],
"text": {
"arc_status": {
"current_arc_key": "timekeeping-linux",
"stage": "early",
"staleness_score": 0.2,
"momentum_score": 0.92,
"short_reason": "Klarer Fortschritt: A/B (pinned vs unpinned) liefert neue Trennung (Migration verstärkt, aber erklärt nicht alle Spikes). Instrumentierung wurde konkret erweitert (seqcount_retry_count, mixed_snapshot_signature) und die offenen Loops sind präziser geworden (IRQ/Preempt vs Publish-Order-Race)."
},
"allowed_move": "deepen",
"topic_changes": {
"new_seed_key": null,
"promote_to_thread_key": null,
"pivot_to_arc_key": null,
"active_threads": []
},
"nudge_block_for_main_workflow": {
"one_liner": "Upgrade die Messung so, dass „versteckte Migration/Preempt/IRQ“ gegen „echtes Publish‑Order‑Race“ sauber getrennt wird – und zwar direkt an den vier no_cpu_switch‑Spikes.",
"beats": [
"Vier no_cpu_switch‑Spikes als Zielmenge festnageln: exakt diese Events komplett annotieren (CPU, preempt, irq/softirq, seqcount‑Retries, Reihenfolge mult/shift/id/baseline).",
"Ein zusätzliches Signal in die Correlation‑ID‑Kette aufnehmen, das Kontextwechsel innerhalb des ±Fensters beweisbar macht (preempt/irq/softirq Marker) und es in trace_agg.py sichtbar machen.",
"Danach ein Mini‑Entscheidungsbaum im Aggregator: (A) Kontextwechsel vorhanden → „hidden-switch“; (B) kein Kontextwechsel, aber Mixed‑Snapshot + seqcount‑Retries → „publish-race‑verdächtig“; CI‑Gate nur auf (B) verschärfen."
],
"tasks": [
{
"type": "build",
"id": "bpf-context-markers-window",
"definition": "eBPF/Tracing erweitern: Für jedes Spike‑Fenster (±5ms, optional parametrisierbar) Marker loggen, ob auf derselben CPU ein preempt/sched_switch passiert ist und ob IRQ/softirq aktiv war (z.B. via tracepoints irq:irq_handler_entry/exit, softirq:softirq_entry/exit, sched:sched_switch) und diese Marker an die bestehende correlation-id hängen. Output: pro Spike ein kompaktes JSON-Feld set {had_sched_switch, had_preempt, had_irq, had_softirq, max_irq_nesting?} plus CPU-ID-Timeline."
},
{
"type": "analysis",
"id": "classify-no_cpu_switch-spikes",
"definition": "Die vier no_cpu_switch‑Fälle aus Ep 521 erneut auswerten: mit den neuen Kontext-Markern klassifizieren in hidden-switch vs publish-race. Zusätzlich Fenster-Sweep: ±5ms vs ±20ms, um zu testen, ob die ‘no_switch’-Fälle nur ein zu enges Fenster sind. Ergebnis: Tabelle (case_id → class, evidence, window_sensitivity) und eine konkrete Empfehlung, welcher Probe‑Punkt als nächstes gesetzt wird (vor/nach mult/shift write oder direkt am seqcount read-side)."
}
],
"do_not_do": [
"Kein neuer Neben-Arc (z.B. EM‑Noise/Fixture) und keine großen CI‑Umbauten, bevor die vier no_cpu_switch‑Spikes eindeutig klassifiziert sind."
]
}
}
}
],
"role": "assistant"
}
]
}
]
Manches ist Null weil es auch der erste Durchlauf ist. Der obere Teil ist mehr für Logs und Themen Speicherung in der Datenbank, der Rest geht so in den Hauptworkflow.
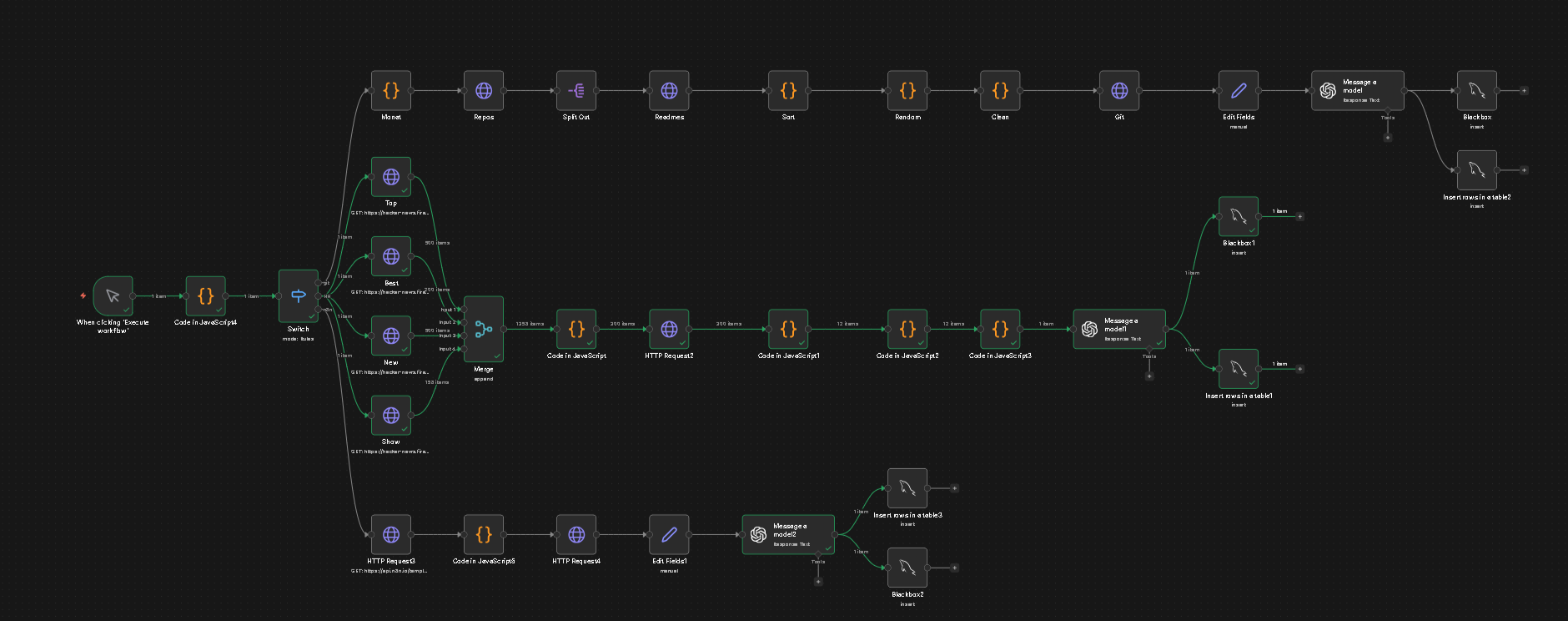
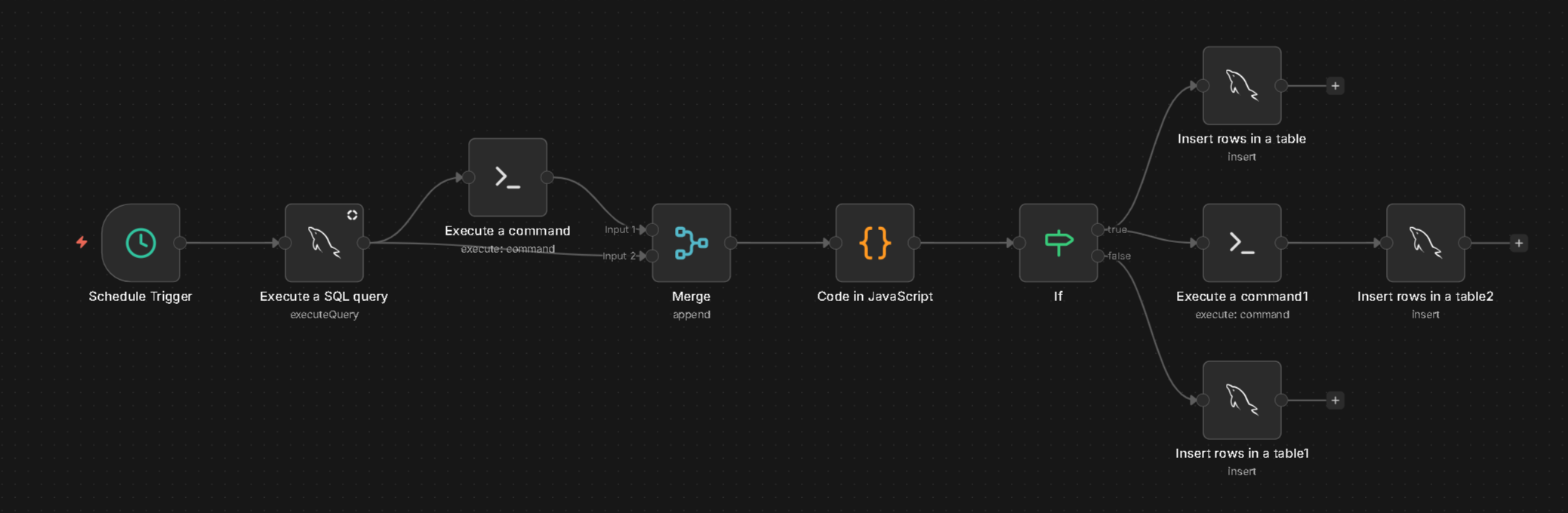
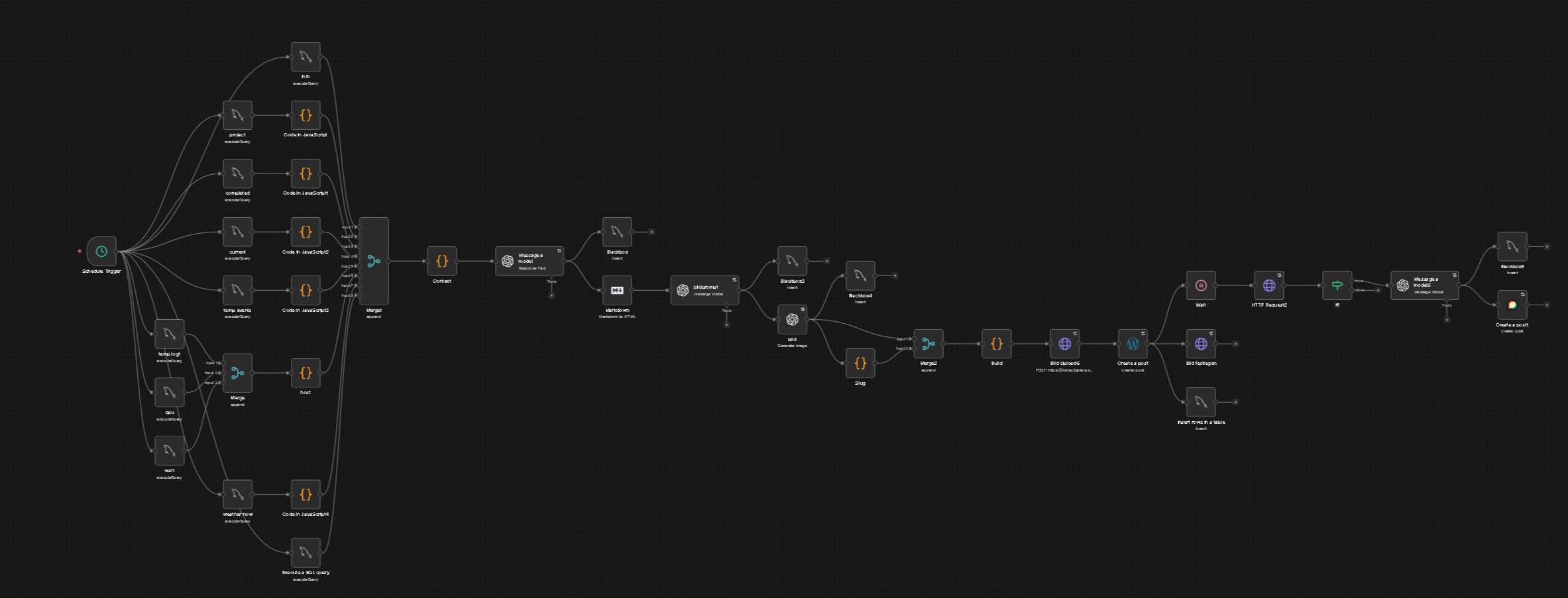
Und so sieht, immernoch, der Mika Workflow aus mit der Nudge v2. Wobei ich hier noch schauen werde, braucht es z.B. auch hier die letzten 30 Tage als Zusammenfassung. Oder z.B. nur den letzten / die letzten drei als Kontext / damit die KI weiß, in welchem Ton geschrieben wird. Bzw. die 30 Tages Zusammenfassung anders schreiben lassen, dass es weniger eine klassische Zusammenfassung ist sondern mehr wann, was, wie, Stichpunkte. Aktuell ist es nen Mischmasch.
Im Kopf ist das irgendwie leichter umsetzen als in der Realität. Das man ein System aufbaut, was die KI schreiben lässt, wie nen normaler Mensch. Dass wenn ein Thema durch ist / nicht weiter kommt, auch was neues ins Spiel bringt. Und dann der Übergang auch gut ist. Aktuell gibt es auch keinen Spielplan wie sich Thematisch das ganze entwickelt. Eine grobe Richtung und eben nicht von heute auf morgen, dass gibt es. Aber wie, wann, ob - soll die KI entscheiden.
Jetzt schau ich mal ab was sich ergeben wird mit dem Nudge v2. Evtl. ist das schon der richtige weg, evtl. auch nicht, dann wird downgegraded oder überarbeitet. Mal schauen.